基于CentOS的Hadoop分布式环境的搭建开发
服务器 发布日期:2025/1/11 浏览次数:1
首先,要说明的一点的是,我不想重复发明轮子。如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录。
其次,我要说的是我也是新手,对于Hadoop也不是很熟悉。但是就是想实际搭建好环境,看看他的庐山真面目,还好,还好,最好看到了。当运行wordcount词频统计的时候,实在是感叹hadoop已经把分布式做的如此之好,即使没有分布式相关经验的人,也只需要做一些配置即可运行分布式集群环境。
好了,言归真传。
在搭建Hadoop环境中你要知道的一些事儿:
1.hadoop运行于Linux系统之上,你要安装Linux操作系统
2.你需要搭建一个运行hadoop的集群,例如局域网内能互相访问的linux系统
3.为了实现集群之间的相互访问,你需要做到ssh无密钥登录
4.hadoop的运行在JVM上的,也就是说你需要安装Java的JDK,并配置好JAVA_HOME
5.hadoop的各个组件是通过XML来配置的。在官网上下载好hadoop之后解压缩,修改/etc/hadoop目录中相应的配置文件
工欲善其事,必先利其器。这里也要说一下,在搭建hadoop环境中使用到的相关软件和工具:
1.VirtualBox——毕竟要模拟几台linux,条件有限,就在VirtualBox中创建几台虚拟机楼
2.CentOS——下载的CentOS7的iso镜像,加载到VirtualBox中,安装运行
3.secureCRT——可以SSH远程访问linux的软件
4.WinSCP——实现windows和Linux的通信
5.JDK for linux——Oracle官网上下载,解压缩之后配置一下即可
6.hadoop2.7.1——可在Apache官网上下载
好了,下面分三个步骤来讲解
Linux环境准备
配置IP
为了实现本机和虚拟机以及虚拟机和虚拟机之间的通信,VirtualBox中设置CentOS的连接模式为Host-Only模式,并且手动设置IP,注意虚拟机的网关和本机中host-only network 的IP地址相同。配置IP完成后还要重启网络服务以使得配置有效。这里搭建了三台Linux,如下图所示




配置主机名字
对于192.168.56.101设置主机名字hadoop01。并在hosts文件中配置集群的IP和主机名。其余两个主机的操作与此类似
[root@hadoop01 ~]# cat /etc/sysconfig/network # Created by anaconda NETWORKING = yes HOSTNAME = hadoop01 [root@hadoop01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.56.101 hadoop01 192.168.56.102 hadoop02 192.168.56.103 hadoop03
永久关闭防火墙
service iptables stop(1.下次重启机器后,防火墙又会启动,故需要永久关闭防火墙的命令;2由于用的是CentOS 7,关闭防火墙的命令如下)
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动
关闭SeLinux防护系统
改为disabled 。reboot重启机器,使配置生效
[root@hadoop02 ~]# cat /etc/sysconfig/selinux # This file controls the state of SELinux on the system # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced # permissive - SELinux prints warnings instead of enforcing # disabled - No SELinux policy is loaded SELINUX=disabled # SELINUXTYPE= can take one of three two values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy Only selected processes are protected # mls - Multi Level Security protection SELINUXTYPE=targeted
集群SSH免密码登录
首先设置ssh密钥
ssh-keygen -t rsa
拷贝ssh密钥到三台机器
ssh-copy-id 192.168.56.101 <pre name="code" class="plain">ssh-copy-id 192.168.56.102
ssh-copy-id 192.168.56.103
这样如果hadoop01的机器想要登录hadoop02,直接输入ssh hadoop02
<pre name="code" class="plain">ssh hadoop02
配置JDK
这里在/home忠诚创建三个文件夹中
tools——存放工具包
softwares——存放软件
data——存放数据
通过WinSCP将下载好的Linux JDK上传到hadoop01的/home/tools中
解压缩JDK到softwares中
<pre name="code" class="plain">tar -zxf jdk-7u76-linux-x64.tar.gz -C /home/softwares
可见JDK的家目录在/home/softwares/JDK.x.x.x,将该目录拷贝粘贴到/etc/profile文件中,并且在文件中设置JAVA_HOME
export JAVA_HOME=/home/softwares/jdk0_111 export PATH=$PATH:$JAVA_HOME/bin
保存修改,执行source /etc/profile使配置生效
查看Java jdk是否安装成功:
java -version
可以将当前节点中设置的文件拷贝到其他节点
scp -r /home/* root@192.168.56.10X:/home
Hadoop集群安装
集群的规划如下:
101节点作为HDFS的NameNode ,其余作为DataNode;102作为YARN的ResourceManager,其余作为NodeManager。103作为SecondaryNameNode。分别在101和102节点启动JobHistoryServer和WebAppProxyServer
下载hadoop-2.7.3
并将其放在/home/softwares文件夹中。由于hadoop需要JDK的安装环境,所以首先配置/etc/hadoop/hadoop-env.sh的JAVA_HOME
(PS:感觉我用的jdk版本过高了)
接下来依次修改hadoop相应组件对应的XML
修改core-site.xml :
指定namenode地址
修改hadoop的缓存目录
hadoop的垃圾回收机制
<configuration>
<property>
<name>fsdefaultFS</name>
<value>hdfs://101:8020</value>
</property>
<property>
<name>hadooptmpdir</name>
<value>/home/softwares/hadoop-3/data/tmp</value>
</property>
<property>
<name>fstrashinterval</name>
<value>10080</value>
</property>
</configuration>
hdfs-site.xml
设置备份数目
关闭权限
设置http访问接口
设置secondary namenode 的IP地址
<configuration>
<property>
<name>dfsreplication</name>
<value>3</value>
</property>
<property>
<name>dfspermissionsenabled</name>
<value>false</value>
</property>
<property>
<name>dfsnamenodehttp-address</name>
<value>101:50070</value>
</property>
<property>
<name>dfsnamenodesecondaryhttp-address</name>
<value>103:50090</value>
</property>
</configuration>
修改mapred-site.xml.template名字为mapred-site.xml
指定mapreduce的框架为yarn,通过yarn来调度
指定jobhitory
指定jobhitory的web端口
开启uber模式——这是针对mapreduce的优化
<configuration>
<property>
<name>mapreduceframeworkname</name>
<value>yarn</value>
</property>
<property>
<name>mapreducejobhistoryaddress</name>
<value>101:10020</value>
</property>
<property>
<name>mapreducejobhistorywebappaddress</name>
<value>101:19888</value>
</property>
<property>
<name>mapreducejobubertaskenable</name>
<value>true</value>
</property>
</configuration>
修改yarn-site.xml
指定mapreduce为shuffle
指定102节点为resourcemanager
指定102节点的安全代理
开启yarn的日志
指定yarn日志删除时间
指定nodemanager的内存:8G
指定nodemanager的CPU:8核
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarnnodemanageraux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarnresourcemanagerhostname</name>
<value>102</value>
</property>
<property>
<name>yarnweb-proxyaddress</name>
<value>102:8888</value>
</property>
<property>
<name>yarnlog-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarnlog-aggregationretain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarnnodemanagerresourcememory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarnnodemanagerresourcecpu-vcores</name>
<value>8</value>
</property>
</configuration>
配置slaves
指定计算节点,即运行datanode和nodemanager的节点
192.168.56.101
192.168.56.102
192.168.56.103
先在namenode节点格式化,即101节点上执行:
进入到hadoop主目录: cd /home/softwares/hadoop-3
执行bin目录下的hadoop脚本: bin/hadoop namenode -format
出现successful format才算是执行成功(PS,这里是盗用别人的图,不要介意哈) 
以上配置完成后,将其拷贝到其他的机器
Hadoop环境测试
进入hadoop主目录下执行相应的脚本文件
jps命令——java Virtual Machine Process Status,显示运行的java进程
在namenode节点101机器上开启hdfs
[root@hadoop01 hadoop-3]# sbin/start-dfssh Java HotSpot(TM) Client VM warning: You have loaded library /home/softwares/hadoop-3/lib/native/libhadoopso which might have disabled stack guard The VM will try to fix the stack guard now It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack' 16/11/07 16:49:19 WARN utilNativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable Starting namenodes on [hadoop01] hadoop01: starting namenode, logging to /home/softwares/hadoop-3/logs/hadoop-root-namenode-hadoopout 102: starting datanode, logging to /home/softwares/hadoop-3/logs/hadoop-root-datanode-hadoopout 103: starting datanode, logging to /home/softwares/hadoop-3/logs/hadoop-root-datanode-hadoopout 101: starting datanode, logging to /home/softwares/hadoop-3/logs/hadoop-root-datanode-hadoopout Starting secondary namenodes [hadoop03] hadoop03: starting secondarynamenode, logging to /home/softwares/hadoop-3/logs/hadoop-root-secondarynamenode-hadoopout
此时101节点上执行jps,可以看到namenode和datanode已经启动
[root@hadoop01 hadoop-3]# jps 7826 Jps 7270 DataNode 7052 NameNode
在102和103节点执行jps,则可以看到datanode已经启动
[root@hadoop02 bin]# jps 4260 DataNode 4488 Jps [root@hadoop03 ~]# jps 6436 SecondaryNameNode 6750 Jps 6191 DataNode
启动yarn
在102节点执行
[root@hadoop02 hadoop-3]# sbin/start-yarnsh starting yarn daemons starting resourcemanager, logging to /home/softwares/hadoop-3/logs/yarn-root-resourcemanager-hadoopout 101: starting nodemanager, logging to /home/softwares/hadoop-3/logs/yarn-root-nodemanager-hadoopout 103: starting nodemanager, logging to /home/softwares/hadoop-3/logs/yarn-root-nodemanager-hadoopout 102: starting nodemanager, logging to /home/softwares/hadoop-3/logs/yarn-root-nodemanager-hadoopout
jps查看各节点:
[root@hadoop02 hadoop-3]# jps 4641 ResourceManager 4260 DataNode 4765 NodeManager 5165 Jps [root@hadoop01 hadoop-3]# jps 7270 DataNode 8375 Jps 7976 NodeManager 7052 NameNode [root@hadoop03 ~]# jps 6915 NodeManager 6436 SecondaryNameNode 7287 Jps 6191 DataNode
分别启动相应节点的jobhistory和防护进程
[root@hadoop01 hadoop-3]# sbin/mr-jobhistory-daemonsh start historyserver starting historyserver, logging to /home/softwares/hadoop-3/logs/mapred-root-historyserver-hadoopout [root@hadoop01 hadoop-3]# jps 8624 Jps 7270 DataNode 7976 NodeManager 8553 JobHistoryServer 7052 NameNode [root@hadoop02 hadoop-3]# sbin/yarn-daemonsh start proxyserver starting proxyserver, logging to /home/softwares/hadoop-3/logs/yarn-root-proxyserver-hadoopout [root@hadoop02 hadoop-3]# jps 4641 ResourceManager 4260 DataNode 5367 WebAppProxyServer 5402 Jps 4765 NodeManager
在hadoop01节点,即101节点上,通过浏览器查看节点状况 
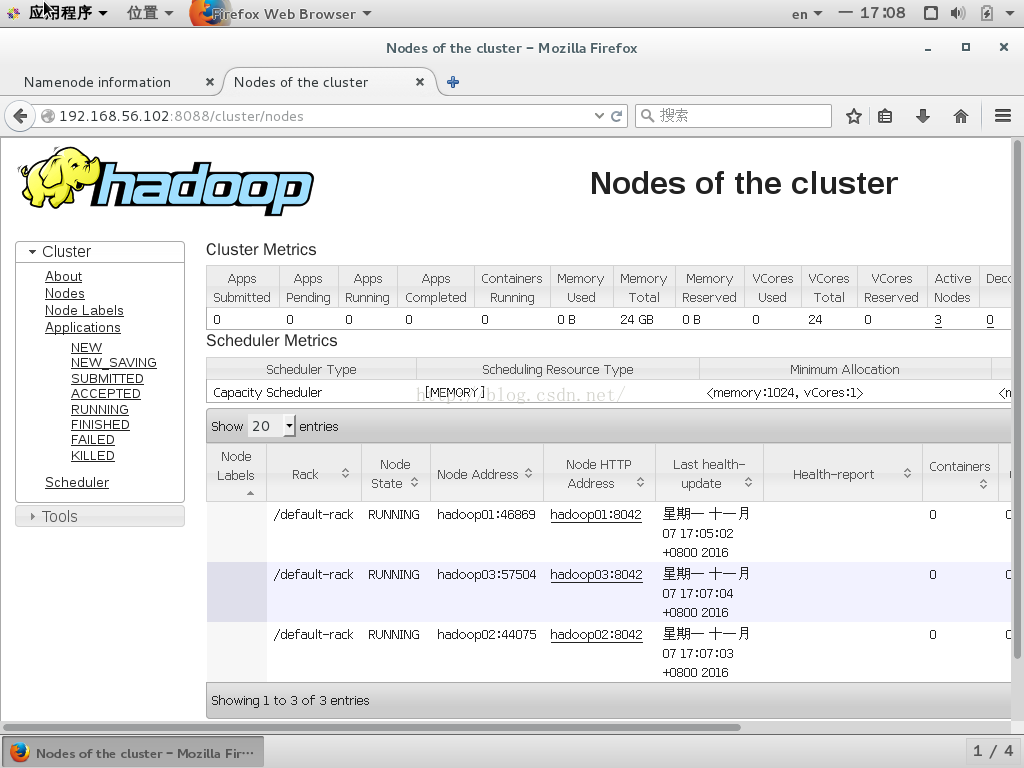
hdfs上传文件
[root@hadoop01 hadoop-3]# bin/hdfs dfs -put /etc/profile /profile
运行wordcount程序
[root@hadoop01 hadoop-3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-jar wordcount /profile /fll_out
Java HotSpot(TM) Client VM warning: You have loaded library /home/softwares/hadoop-3/lib/native/libhadoopso which might have disabled stack guard The VM will try to fix the stack guard now
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'
16/11/07 17:17:10 WARN utilNativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable
16/11/07 17:17:12 INFO clientRMProxy: Connecting to ResourceManager at /102:8032
16/11/07 17:17:18 INFO inputFileInputFormat: Total input paths to process : 1
16/11/07 17:17:19 INFO mapreduceJobSubmitter: number of splits:1
16/11/07 17:17:19 INFO mapreduceJobSubmitter: Submitting tokens for job: job_1478509135878_0001
16/11/07 17:17:20 INFO implYarnClientImpl: Submitted application application_1478509135878_0001
16/11/07 17:17:20 INFO mapreduceJob: The url to track the job: http://102:8888/proxy/application_1478509135878_0001/
16/11/07 17:17:20 INFO mapreduceJob: Running job: job_1478509135878_0001
16/11/07 17:18:34 INFO mapreduceJob: Job job_1478509135878_0001 running in uber mode : true
16/11/07 17:18:35 INFO mapreduceJob: map 0% reduce 0%
16/11/07 17:18:43 INFO mapreduceJob: map 100% reduce 0%
16/11/07 17:18:50 INFO mapreduceJob: map 100% reduce 100%
16/11/07 17:18:55 INFO mapreduceJob: Job job_1478509135878_0001 completed successfully
16/11/07 17:18:59 INFO mapreduceJob: Counters: 52
File System Counters
FILE: Number of bytes read=4264
FILE: Number of bytes written=6412
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3940
HDFS: Number of bytes written=261673
HDFS: Number of read operations=35
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=8246
Total time spent by all reduces in occupied slots (ms)=7538
TOTAL_LAUNCHED_UBERTASKS=2
NUM_UBER_SUBMAPS=1
NUM_UBER_SUBREDUCES=1
Total time spent by all map tasks (ms)=8246
Total time spent by all reduce tasks (ms)=7538
Total vcore-milliseconds taken by all map tasks=8246
Total vcore-milliseconds taken by all reduce tasks=7538
Total megabyte-milliseconds taken by all map tasks=8443904
Total megabyte-milliseconds taken by all reduce tasks=7718912
Map-Reduce Framework
Map input records=78
Map output records=256
Map output bytes=2605
Map output materialized bytes=2116
Input split bytes=99
Combine input records=256
Combine output records=156
Reduce input groups=156
Reduce shuffle bytes=2116
Reduce input records=156
Reduce output records=156
Spilled Records=312
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=870
CPU time spent (ms)=1970
Physical memory (bytes) snapshot=243326976
Virtual memory (bytes) snapshot=2666557440
Total committed heap usage (bytes)=256876544
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1829
File Output Format Counters
Bytes Written=1487
浏览器中通过YARN查看运行状态 
查看最后的词频统计结果
浏览器中查看hdfs的文件系统
[root@hadoop01 hadoop-3]# bin/hdfs dfs -cat /fll_out/part-r-00000
Java HotSpot(TM) Client VM warning: You have loaded library /home/softwares/hadoop-3/lib/native/libhadoopso which might have disabled stack guard The VM will try to fix the stack guard now
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'
16/11/07 17:29:17 WARN utilNativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable
!= 1
"$-" 1
"$2" 1
"$EUID" 2
"$HISTCONTROL" 1
"$i" 3
"${-#*i}" 1
"0" 1
":${PATH}:" 1
"`id 2
"after" 1
"ignorespace" 1
# 13
$UID 1
&& 1
() 1
*) 1
*:"$1":*) 1
-f 1
-gn`" 1
-gt 1
-r 1
-ru` 1
-u` 1
-un`" 2
-x 1
-z 1
2
/etc/bashrc 1
/etc/profile 1
/etc/profiled/ 1
/etc/profiled/*sh 1
/usr/bin/id 1
/usr/local/sbin 2
/usr/sbin 2
/usr/share/doc/setup-*/uidgid 1
002 1
022 1
199 1
200 1
2>/dev/null` 1
; 3
;; 1
= 4
>/dev/null 1
By 1
Current 1
EUID=`id 1
Functions 1
HISTCONTROL 1
HISTCONTROL=ignoreboth 1
HISTCONTROL=ignoredups 1
HISTSIZE 1
HISTSIZE=1000 1
HOSTNAME 1
HOSTNAME=`/usr/bin/hostname 1
It's 2
JAVA_HOME=/home/softwares/jdk0_111 1
LOGNAME 1
LOGNAME=$USER 1
MAIL 1
MAIL="/var/spool/mail/$USER" 1
NOT 1
PATH 1
PATH=$1:$PATH 1
PATH=$PATH:$1 1
PATH=$PATH:$JAVA_HOME/bin 1
Path 1
System 1
This 1
UID=`id 1
USER 1
USER="`id 1
You 1
[ 9
] 3
]; 6
a 2
after 2
aliases 1
and 2
are 1
as 1
better 1
case 1
change 1
changes 1
check 1
could 1
create 1
custom 1
customsh 1
default, 1
do 1
doing 1
done 1
else 5
environment 1
environment, 1
esac 1
export 5
fi 8
file 2
for 5
future 1
get 1
go 1
good 1
i 2
idea 1
if 8
in 6
is 1
it 1
know 1
ksh 1
login 2
make 1
manipulation 1
merging 1
much 1
need 1
pathmunge 6
prevent 1
programs, 1
reservation 1
reserved 1
script 1
set 1
sets 1
setup 1
shell 2
startup 1
system 1
the 1
then 8
this 2
threshold 1
to 5
uid/gids 1
uidgid 1
umask 3
unless 1
unset 2
updates 1
validity 1
want 1
we 1
what 1
wide 1
will 1
workaround 1
you 2
your 1
{ 1
} 1
这就代表hadoop集群正确
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
在此次发布会上,英特尔还发布了全新的全新的酷睿Ultra Meteor Lake NUC开发套件,以及联合微软等合作伙伴联合定义“AI PC”的定义标准。